
Assessing value through software architecture
Talking to architects in the community surrounding IDesign’s The Method, it is often said that there is little opportunity to apply the method in real life scenarios. A lot of people seem to think that The Method shines in greenfields and that that is its only use.
Another topic I find myself talking about with peers is that of “businesspeople want answers too fast”. Being it answers on project cost, work effort or quality. This can be very uncomfortable for engineering-minded people. Because you need to know what you’re estimating and need to work through a few things before you can give numbers.
In this post I explore a real-life review scenario, where The Method’s techniques were used to deliver answers to the question of the customer without lengthy in-depth engineering sessions: is my project a viable project to support in the future?
The entire flow took me a little less than 2 days, where it was a 20:70:10 ratio on preparation vs spelunking vs writing a report.
Setting the scene
Recently, we were asked to perform an audit on a system. Our customer had invested a large sum of money into a system that performs certain activities but due to circumstances the person that was involved in building this project could no longer continue work. Now, our customer has a problem: is this system a living thing that can bring in the revenue it was supposed to? Or is it a dud?
I hope you can sense this is a matter of great importance to the customer. Answering this correctly is the difference between investing and winning money vs digging a deeper hole. To top it off, a customer in this situation doesn’t want to wait 30 days to analyze whatever this thing is. They already invested a ton in it, and they wanted an answer yesterday. We must find a way to give as much information as possible within a limited timeframe. Using the information coming out of the review, next steps will be taken.
Truth be told, our knee-jerk reaction was to go for a 15 to 20-day analysis bid. We received information about the system and immediately knew there were some aspects of it that would require careful analysis if we were to take over this application. Setting up a test environment would’ve been a nightmare. However, that was not the question. So we decided to shift gears and review on a higher level.
I will assume you have some familiarity with The Method (if not, see Juval’s book, Righting Software). The consistency it provides across systems is rivalled by none in the industry today, let’s use that to our advantage.
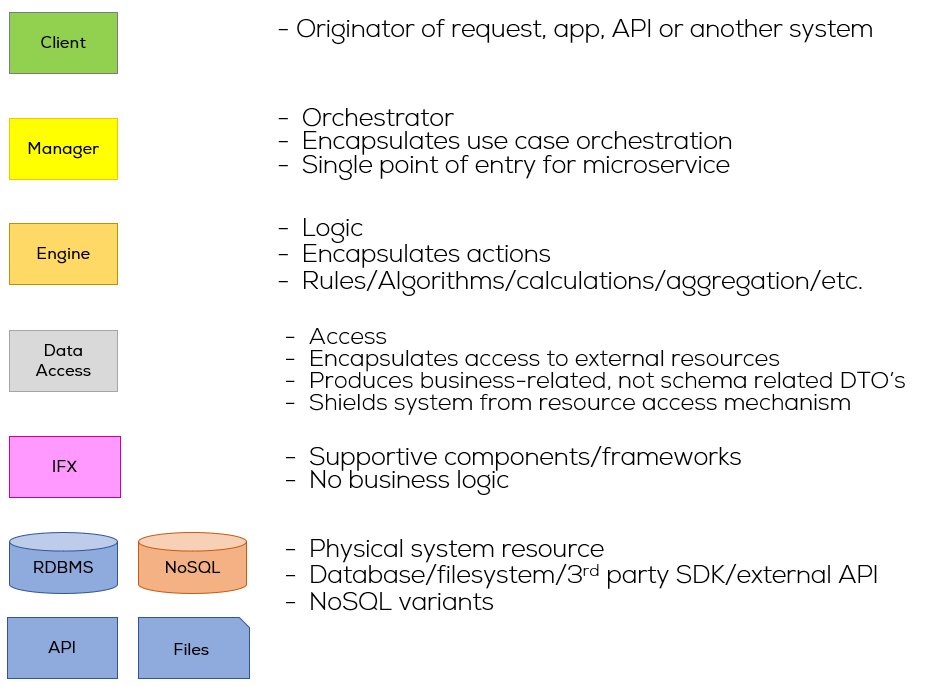
Starting an audit assignment, the main questions are:
- Does the system do what it’s supposed to do?
- Does it do that in a structured way, or is there no architecture and just things that happen to work together?
- And in whatever fashion it was constructed, does it hold up to any code quality metrics we know to be important?
As this project is something like pre-alpha, it requires a lot of future updates. It’s always a guess on how these things will unfold, or even when you will find an answer to your questions. It can be starting the first conversation; it can be that you need days to review before you can say something to the customer about the quality or value of it all. It is not because you have a great architecture, that the code quality is good nor does the architecture say anything about the actual value of the intellectual property in the code. A good indicator, but insufficient to success.
Using Method design patterns however, our search becomes a lot easier. There are things we know we need to see, regardless of how they are built in detailed design. If we know the patterns we need to look for, we know when to give it a thumbs up, or thumbs down. At least on the design front.
The Architecture
I am unable to go into the specifics of the system, but I can give you some patterns:
In this case, there was a very specific set of constructs that should be present in the system.
- a streaming ingress system. Ingesting data from several sources for future analysis,
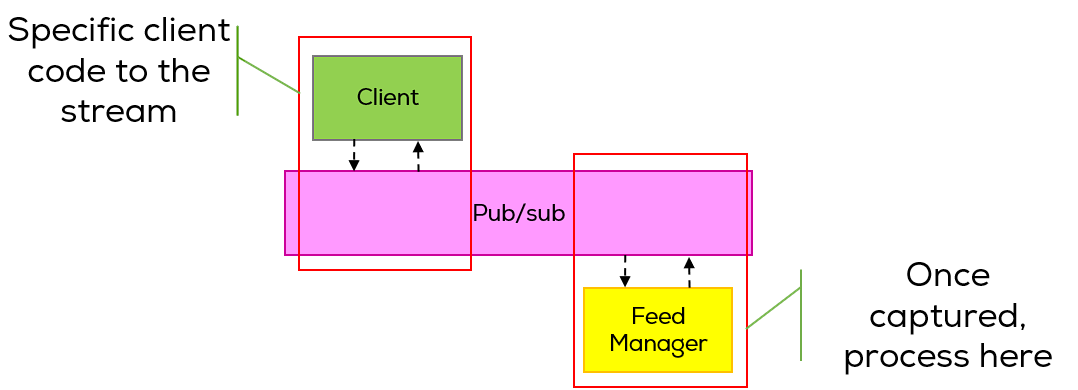
In the best-case scenario, we see a decoupling of getting the streams/things off the internet and the way we process it. If all is done in the same flow or process, the rate at which it gets processed is determined by the stream itself, and we can’t scale.
- an analysis subsystem that uses ML techniques to perform its job,
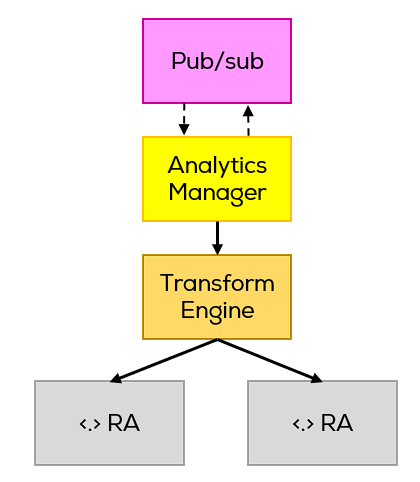
In the best-case scenario, this would be the part of the system that processes the data coming in, on its own terms. And it can evolve separately from the rest of the system.
- And lastly, the system should also have some security components in place (fraud detection, user management, login system, alerting system).
The Analysis
The system was shown to be in working order. The system itself was stable in the sense that it didn’t crash when you were using it. But what it was supposed to do still had some kinks, but all in all the customer was somewhat happy with that part. If “it runs”, we’re already in a better position than many other systems in development out there. 1 thumb up so far.
The situation was such that I was told the person was a VB.net developer and that all the code was delivered. VB.net… you’re thinking ASP.net, webforms, maybe winforms. If it’s netcore, then the most likely suspects is ASP.net.
We received a dump of files of around 100 GB. Around 5 GB of those were in the sources directory. The other 90+ GB was a SQL dump. Okay. So, we received a backup and hopefully a source folder with a lot of binaries in, as 5 GB of code is just insane.
The first step in any analysis for me is exploratory. “What happens when I push here”-sort of thing. This exploratory testing helps me get my bearings; it answers questions like:
- Can I open the sln(s) without any issues?
- Is there a structure that I recognize?
- Can I find the architectural patterns from the solution already?
Smell #1
When looking at the folder structure, I had multiple .sln files. Multipe csproj’s and multiple vbproj’s. Folder names are names coming from public github repositories and things like “test”-this or “test”-that.
Strike 1.
It’s a bad sign when languages like C# and vb are getting mixed in a single project. The second bad sign is the many test pre- and suffixes. Not to mention the author’s desire to create a second GitHub with all of these public repo’s in the main solution.
Smell #2
A reasonably easy technique that can quickly give insights is to look at the methods classes expose. Consequently, you also need to look for class names that have names that make sense.
All of the projects that didn’t come from the web had on average 1 file: Program.cs or Main.vb. These were all console projects. Everything is managed through Windows Services. And yes, there are console applications registered as a Windows Service that see if other services are still running and responding and acting when needed.
These Main.vb or Program.cs files usually had 10-20 methods.
This also means that most of my analysis tools wouldn’t really bring in much value into finding a structure. These tools all work well great if there are multiple projects and multiple classes. They visually help you navigate the zoo. As this is a 1-file per project and 20-methods per class kind of project their use is severely limited. They helped me on other aspects of the review, but not this.
That’s strike 2.
At this point the spidey sense is tingling. This is not a high-quality codebase: no testing, no service orientation concepts, almost no structure except for starting and stopping applications that have a very narrow scope. This brings me back to how development was done in the early 2000’s by a lot of people. If you’ve done a couple of reviews of legacy, 1 or 2-person systems. You know that this type of codebase has been made by keep-it-simple-stupid personalities that don’t know how software systems should be run at scale.
I don’t usually go this deep in the code on this pass, but I was willing to make an exception here. It’s time to take some of these custom projects and see in a little more detail what’s going on…
Smell #3
If all this code that’s written by the guy, is all in one file per project. There’s too little code here for what the system is supposed to be doing. So, what’s going on?
What did I find? Stored procs. The existing .net code was not doing much of anything, it was calling stored procs and that was about it. So now I know the code dump of 5 GB was mostly binaries and a ton of GitHub repo’s not really doing much. But it’s doing a little orchestration of some dataflows and starting stored procs.
Strike 3.
You can argue that SQL development is a viable way to develop products. I’m sorry but it’s not. There’s simply no way to justify thinking of SQL Server as a development platform for web-based applications anno 2000+.
Smell #4
Let’s open up SSMS, look at stored procedures. Right. 200+ SP’s, 200+ views. Oh dear. Now I must figure out if the SQL code has any structure to it.
You can do triggers and create queueing behavior in SQL so he could have structured it somehow. The patterns still apply, they are irrespective of used technology. The tools and services will look different, but they should be there.
After some manual analysis, Joeri and I found the “entry point of the system“. And we did indeed find the flow of the patterns we were looking for after a short investigation. Sort of.
In the end the current system architecture looks something like this:
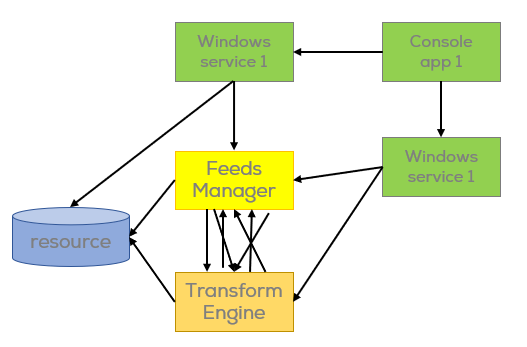
- No queueing
- No separation of concerns
- No structured code patterns
- Lots of duplicate code
- Data flowing in all directions
- Naming smells
- Bad/ugly/unstructured queries
Tying together what we saw in the .net and the SQL world we could surmise that the system contained valid IP, however for it to be able to do what it was supposed to do, at the scale it was supposed to do it, it was not on-quality. For what it was supposed to do, it should run on a data center or a cloud environment across several servers. The only conclusion we could draw was that it needed a rewrite. A rewrite into a language and with an architecture that can embrace mature constructs and that can scale with the customer needs.
Conclusion
Reviews and audits can take you on rollercoaster. The first thing to do is to get an architecture on paper, as if you were to design and build the system yourself. This forces you to think what the structure could be. Don’t take this exercise too far, you’re here for the review, not the design. Moreover, it’s only one of many possible designs.
Once you have that, you can look at what’s going on in the code. First, only looking at the structure of it, then you can start looking at high level code: interface-level code and class-level methods can give you a good idea of what’s what. Use your favorite tools to help you diagram and find out what’s going on: Visual Studio, NDepend, … If that doesn’t help? Good old fashioned elbow grease: finding the structure in the code. Again, keep in mind that you need to be efficient and effective here. Your goal is not to rebuild the system, it’s not to fully document the system. But your goal is to get to a point where you can say in terms of risk: is it safe to continue to build on this system? You need quality metrics to help back you up. Both code quality and architectural quality.
Once that you can put architecture and code together, you can assess the situation and give an informed status of what the codebase is and if the IP is available. The next steps are then to work through a project design to give numbers to your customer about what it would mean to build this system for real.